在进行大数据处理时,有许多工具可供选择,下面是我为您列举的十大工具:
1. Apache Hive:Hive是一个建立在Hadoop上的开源数据仓库基础设施,可以轻松地进行数据的ETL(提取、转换、加载)操作,对数据进行结构化处理,并对Hadoop上的大数据文件进行查询和处理等。它还提供了一种类似于SQL的查询语言——HiveQL,方便熟悉SQL语言的用户查询数据。
2. Actian:Actian之前被称为IngresCorp,它拥有超过一万家客户并正在不断扩大。它通过Vectorwise以及对ParAccel实现了扩展。
3. Apache Hadoop:Apache Hadoop是一个允许在商用硬件集群上处理大规模数据的开源软件平台。它允许在商用硬件集群上处理大规模数据。
4. Hortonworks:Hortonworks是另一个允许在商用硬件集群上处理大规模数据的开源软件平台。
5. Cloudera:Cloudera提供了一个称为Impala的快速查询引擎,它可以在Hadoop上执行SQL查询。
6. MapR:MapR是一个对Apache Hadoop的商业化发行版,它提供了一些额外的功能,例如在商用硬件集群上处理大规模数据的快速查询。
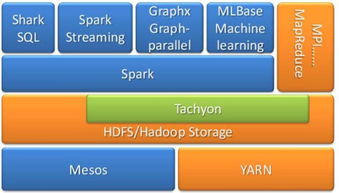
7. Apache Spark:Apache Spark是一个用于大规模数据处理的统一分析引擎。它提供了包括SQL查询、流处理、机器学习和图处理等在内的一体化的API。
8. RapidMiner:RapidMiner是一个用于数据挖掘和机器学习的开源软件平台。它提供了一个易于使用的界面和强大的功能,例如数据预处理、分类、聚类和可视化等。
9. Karmasphere Studio and Analyst:Karmasphere Studio是一组构建在Eclipse上的插件,它提供了一个更易于创建和运行Hadoop任务的专用IDE。Karmasphere Analyst是一个用于大数据分析的交互式可视化环境。
10. Pentaho Business Analytics:Pentaho Business Analytics是一个用于大数据处理的商业智能软件平台。它提供了一个易于使用的界面和强大的功能,例如数据挖掘、报表生成、数据可视化等。
这些工具各有各的优势和适用场景,您可以根据自己的需求选择合适的工具来处理大数据。
为了更有效地进行数据处理,人们不断探索和开发各种工具。本文将为您介绍大数据处理必备的十大工具,帮助您提高数据处理效率和准确性。
1. Hadoop
Apache Hadoop是一个分布式计算框架,可处理大规模数据集。它允许在商用硬件集群上处理数据,同时提供数据备份和容错功能。Hadoop的两大核心组件是HDFS(分布式文件系统)和MapReduce(编程模型)。
2. Spark
Apache Spark是另一个流行的分布式计算框架,专门用于大规模数据处理。与Hadoop相比,Spark更注重内存存储和计算速度。Spark提供了丰富的API和工具,包括Spark SQL、MLlib(机器学习库)和GraphX(图计算库)。
3. Flik
Apache Flik是另一个分布式流处理和批处理框架,具有高性能、低延迟和可扩展性等特点。Flik提供了基于Java和Scala的API,以及用于状态计算的RocksDB存储后端。
4. Kafka
Apache Kafka是一个分布式流处理平台,用于构建实时数据管道和流应用程序。它提供了高吞吐量、可扩展性和容错性,支持发布和订阅消息模式。Kafka广泛应用于日志收集、事件驱动微服务和实时分析等领域。
5. Sorm
Apache Sorm是一个分布式实时计算系统,可以处理高速数据流。它提供了可扩展的拓扑结构和容错机制,支持各种编程语言。Sorm广泛应用于实时分析、在线机器学习和实时数据处理等领域。
6. Giraph
Giraph是一个分布式图计算框架,支持大规模图数据处理。它基于Google的Pregel模型,适用于社交网络、推荐系统和网络分析等领域。Giraph提供了可扩展的API和工具,使开发人员能够轻松地构建并行图应用程序。
7. Hive
Apache Hive是一个数据仓库基础设施,为大数据分析提供了SQL界面和命令行界面。它允许用户通过HiveQL查询和分析大规模数据集,同时支持自定义MapReduce作业和HiveServer2 REST API。Hive广泛应用于数据仓库、数据湖和数据湖激活等领域。
8. Pig
Apache Pig是一个基于Hadoop的数据流语言和运行环境,用于大规模数据分析。它允许用户使用简单的Pig Lai语言编写数据处理脚本,并在Hadoop集群上执行。Pig广泛应用于数据管道、ETL和数据挖掘等领域。
9. Impala
Cloudera Impala是一个开源的分布式SQL查询引擎,用于快速查询大规模数据集。它允许用户使用熟悉的SQL语法查询Hadoop和Apache HBase中的数据,而无需编写复杂的MapReduce作业。Impala广泛应用于报表生成、即席查询和实时分析等领域。
10. Beam
Apache Beam是一个统一的编程模型和执行引擎,用于处理批处理和流数据处理任务。它允许开发人员使用可扩展的API(如Java、Pyho和Go)编写数据处理管道,并支持多种数据处理引擎(如Apache Flik、Apache Spark和Google Cloud Daaflow)。Beam广泛应用于数据管道、批处理和流数据处理等领域。


 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条